Large language models forget everything between calls. The engineering trick that makes enterprise assistants feel like they remember you is mostly clever plumbing, not bigger context windows, and the economics of that plumbing decide whether a feature ships or dies.
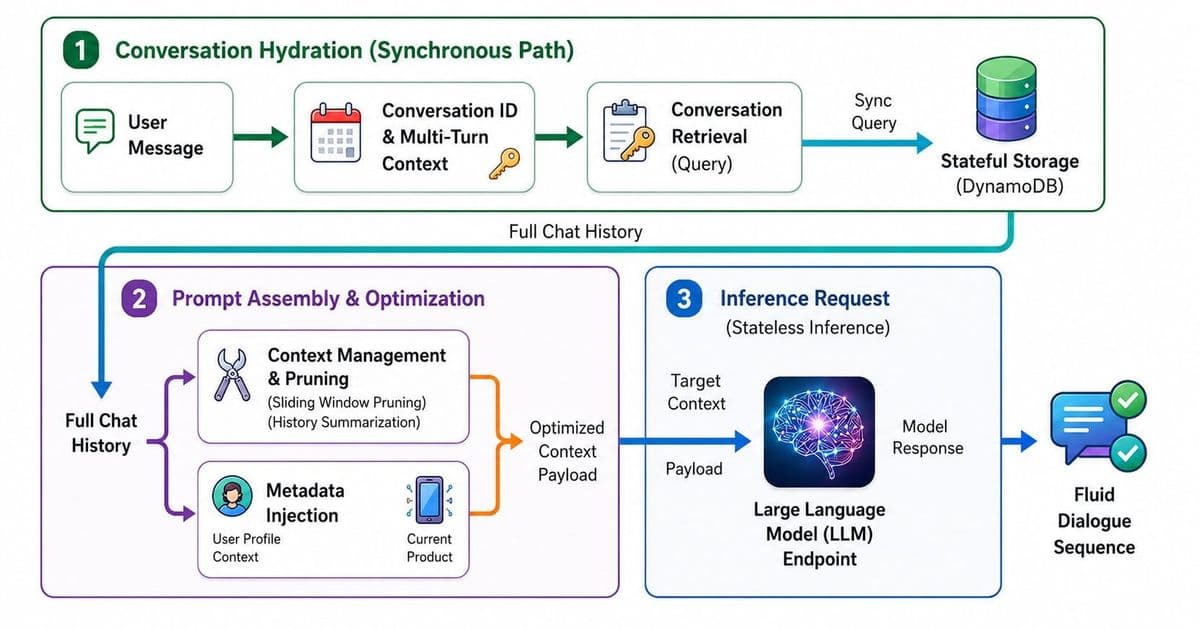
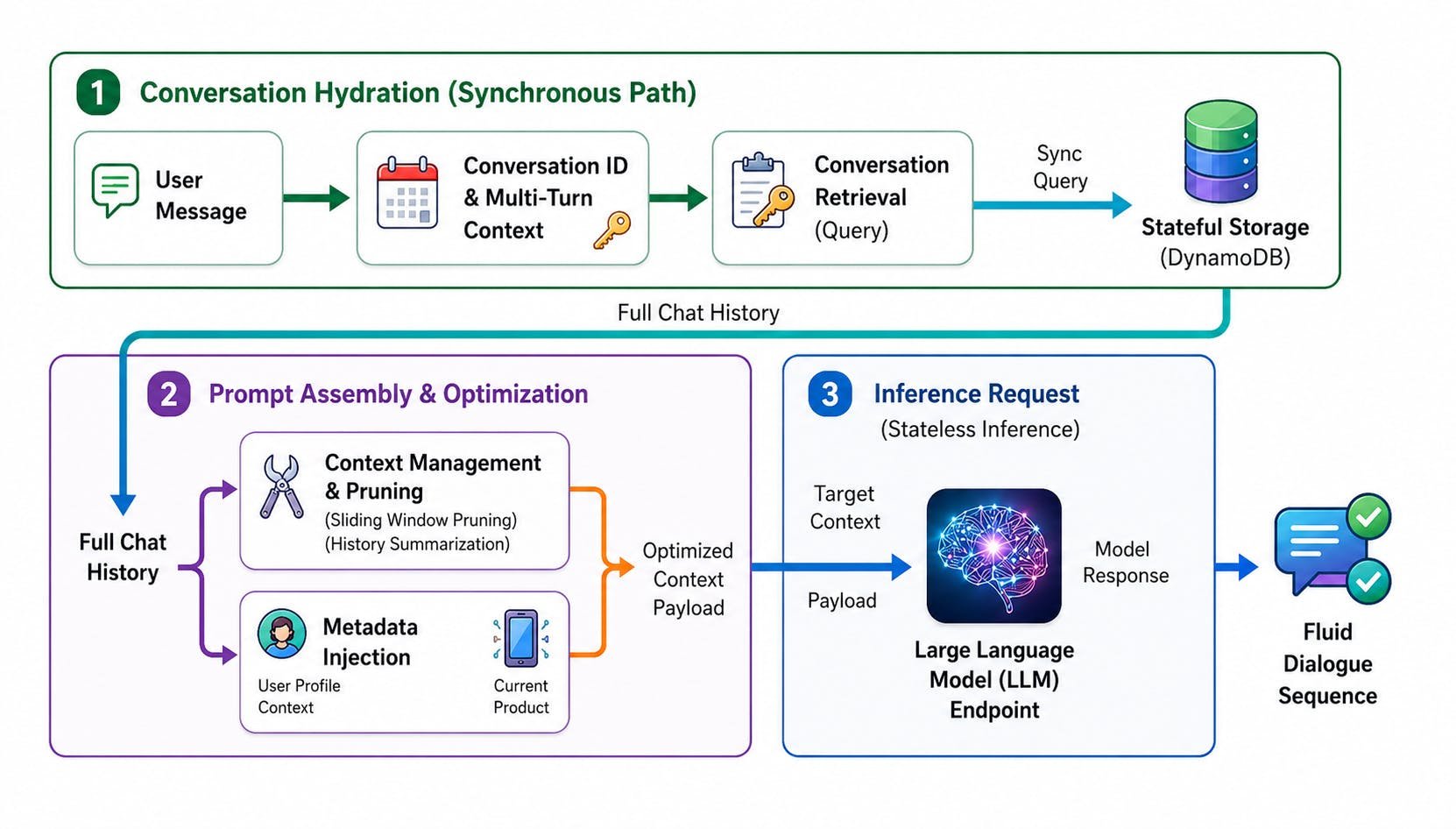
Every conversation with a stateless language model starts from zero. The model that answered your last three questions has no recollection of them. What feels like memory in a production AI assistant is an illusion stitched together outside the model, in retrieval layers, summarization passes, and storage systems that decide what gets fed back into a finite context window. Aditi's writeup on the subject lays out the architecture that enterprise teams actually use, and it is worth pulling apart because the constraints are not academic. They are about money.
The problem is the bill, not the technology
A token is the unit of text a model reads and writes, roughly three quarters of a word. Every token in the prompt costs money and adds latency. A context window is the maximum number of tokens a model can consider at once. Modern models advertise windows of hundreds of thousands of tokens, which sounds like it should solve memory outright. Just stuff the entire conversation history in and let the model sort it out.
The catch is that you pay for every one of those tokens on every single call. If an assistant carries a 100,000 token history and a user sends 50 messages in a session, you are re-billing the full history dozens of times. At enterprise scale, with thousands of concurrent users, that arithmetic turns a useful feature into a line item nobody will approve. The interesting engineering is not how to give a model more memory. It is how to give the impression of memory while sending as few tokens as possible.
Memory as a tiered storage problem
The pattern that has settled into place treats conversational memory the way operating systems treat data: hot, warm, and cold tiers, each with different cost and access characteristics.
The hot tier is the recent message buffer, the last handful of exchanges kept verbatim in the prompt. This is cheap because it is small and it preserves the immediate flow of conversation. The warm tier is a running summary. Once messages fall out of the recent buffer, a separate model call compresses them into a dense paragraph, trading fidelity for token efficiency. Instead of replaying twenty messages, you replay one summary that captures their gist. The cold tier is external storage, where full transcripts and extracted facts live in a database and get pulled back in only when relevant.
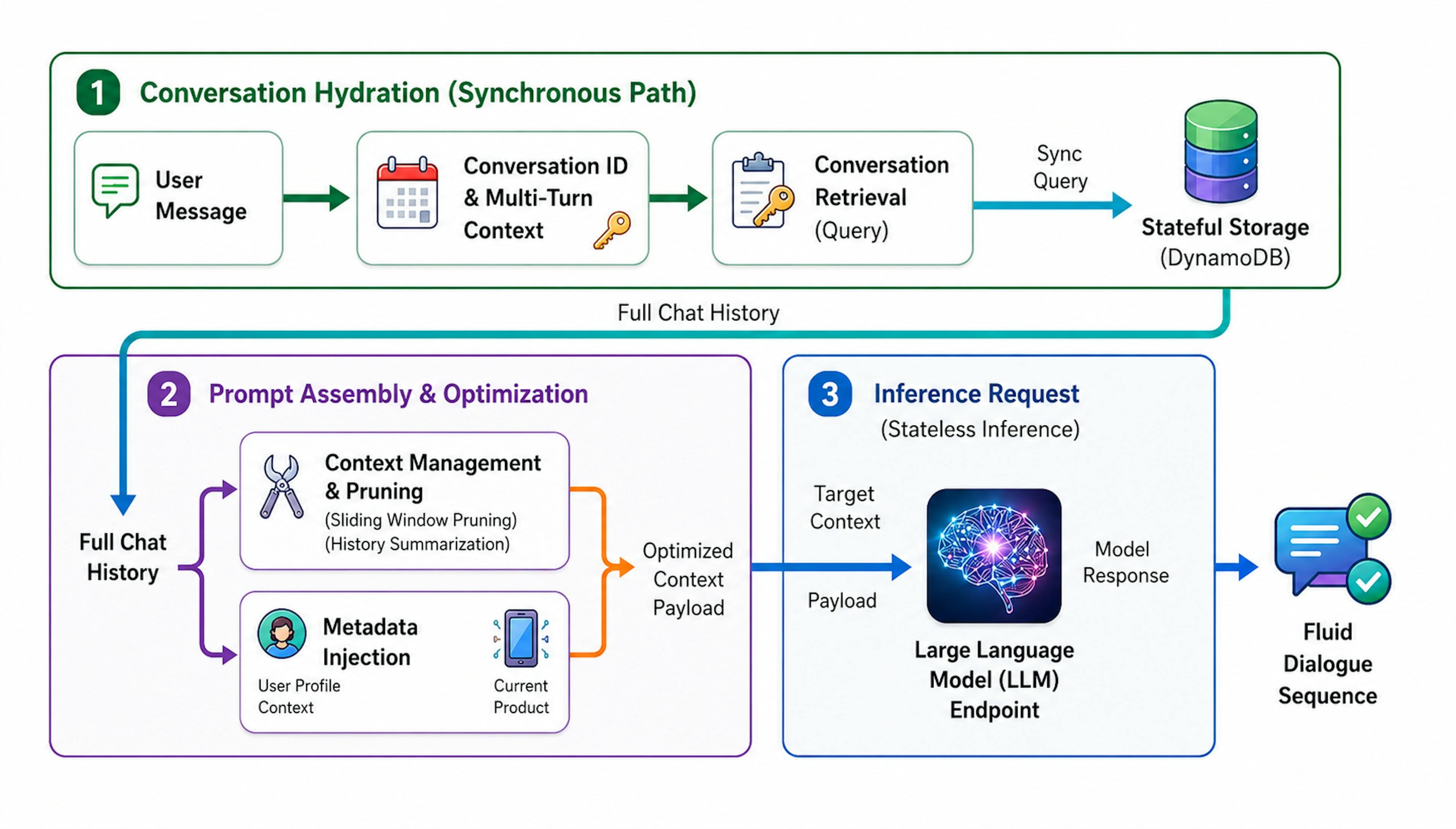
That cold tier is where systems like DynamoDB enter the picture. A key-value store gives you fast, predictable lookups keyed by user and session, which is exactly the access pattern conversational memory needs. You are rarely scanning across users. You are fetching one person's history, fast, on every turn. The storage is cheap relative to token costs, so pushing history out of the prompt and into a database is almost always the right trade.
Retrieval is the hard part
Keeping a summary and a transcript store is straightforward. Deciding what to surface from cold storage at the right moment is where most implementations succeed or fail. The dominant approach is retrieval-augmented generation, where user messages get converted into vector embeddings and matched against stored memories by semantic similarity. Ask about a project you mentioned three weeks ago, and the system retrieves the relevant chunk and injects it into the prompt, so the model appears to recall something it was never told in this session.
The failure modes are instructive. Retrieve too little and the assistant feels forgetful, contradicting things the user clearly stated. Retrieve too much and you are back to bloating the context window, paying for tokens that add noise instead of signal. Semantic search also retrieves things that are topically similar but contextually wrong, which produces the unsettling experience of an assistant confidently referencing a detail that does not apply. Tuning the retrieval threshold, the number of chunks pulled, and how aggressively summaries compress is the real work, and it is workload-specific. A customer support bot and a coding assistant want very different memory policies.
Summarization compounds its own errors
The warm tier carries a subtle risk. Each time you summarize a summary, you lose information, and the losses accumulate. A fact mentioned once and folded into a paragraph, then folded again into a higher-level summary, can vanish entirely or mutate into something the user never said. Teams handle this by extracting structured facts separately, pulling out durable items like names, preferences, and decisions into explicit key-value records rather than trusting prose summaries to retain them. The summary handles narrative flow, the structured store handles facts that must survive, and the two are reconciled at retrieval time.
This split matters for correctness. Prose is lossy and unauditable. A structured record saying the user prefers metric units is something you can inspect, update, and delete. As privacy regulations push harder on the right to have data erased, that auditability stops being a nicety and becomes a requirement. You cannot reliably delete a fact that exists only as an implication inside a compressed paragraph.
What this means for teams building on top of models
The takeaway from Aditi's piece is that memory is an orchestration problem, not a model capability you wait for vendors to deliver. The context window will keep growing, but the economics of re-billing tokens on every call will not change, so the tiered approach has staying power regardless of how large windows get. Teams shipping AI features should budget for the memory layer as a distinct system with its own storage costs, latency characteristics, and tuning burden, rather than assuming a bigger model makes the problem disappear.

The broader pattern is familiar to anyone who has built distributed systems. You are managing a cache hierarchy, balancing freshness against cost, and accepting that perfect recall is too expensive so you engineer for good-enough recall at a price that works. The novelty is only in the substrate. Vectors and summaries instead of pages and blocks. The discipline of deciding what to keep close and what to evict is the same one infrastructure engineers have practiced for decades, now applied to the strange new problem of making a stateless model feel like it knows you.
Comments
Please log in or register to join the discussion