
Microsoft Foundry now hosts the Qwen3.5 Medium Model Series from Hugging Face, offering three Vision Language Models ranging from 27B to 122B parameters with early-fusion multimodal training and support for 201 languages.
Microsoft has expanded its Foundry AI platform with the addition of the Qwen3.5 Medium Model Series, a collection of three Vision Language Models (VLMs) now available through Hugging Face integration. These models represent a significant advancement in multimodal AI capabilities, offering developers scalable options for vision-language tasks ranging from real-time quality inspection to complex financial analysis.

Three Models, One Family
The Qwen3.5 Medium series consists of three distinct models, each optimized for different deployment scenarios:
Qwen3.5-27B serves as the dense baseline with 27 billion parameters, activating all parameters on every forward pass. This architecture provides predictable latency, making it ideal for real-time applications where consistent response times are critical. The model achieves a 95.0 score on IFEval and 76.5 on IFBench, leading the family in instruction-following capabilities.
Qwen3.5-35B-A3B introduces Mixture-of-Experts (MoE) architecture with 35 billion total parameters but only 3 billion activated per inference call. This configuration delivers performance approaching much larger dense models while significantly reducing computational costs. The model uses 256-expert MoE routing, with each token passing through 8 of 256 experts plus one shared expert.
Qwen3.5-122B-A10B represents the flagship model with 122 billion total parameters and 10 billion activated per token. This model leads the family across most benchmarks, achieving 76.9 on MMMU-Pro, 83.9 on MMMU, and 86.7 on MMLU-Pro. Its larger routing pool and higher active parameter count make it suitable for the most demanding multimodal tasks.
Architectural Innovations
All three models share several key architectural advances that distinguish them from previous generations:
Unified Vision-Language Training employs early-fusion multimodal training, where text and image tokens are processed together from the beginning rather than attaching separate vision encoders as an afterthought. This approach enables stronger reasoning over diagrams, charts, and documents compared to the prior Qwen3-VL models that used separate vision pipelines.
Gated Delta Networks replace standard self-attention in most transformer layers with a novel linear attention mechanism. Combined with sparse MoE routing in the larger models, this hybrid architecture delivers high-throughput inference at lower latency than equivalent dense architectures.
Scalable Reinforcement Learning across agent environments contributes to strong performance on instruction-following and agentic task benchmarks. The post-training process uses reinforcement learning scaled across large multi-agent environments, enhancing the models' ability to handle complex, multi-step instructions.
Practical Applications
The Qwen3.5 Medium series addresses diverse use cases across industries:
Manufacturing Quality Inspection: The 27B model excels at processing images from production line cameras to identify defects in printed circuit boards. A typical deployment would analyze images for solder bridges, missing components, or misaligned pads, returning structured JSON with defect type, location, and severity ratings.
Legal Document Analysis: The 35B-A3B model serves as an efficient contract review assistant for legal teams. It can process scanned contract pages to extract defined terms, identify obligation and liability clauses, and flag termination conditions that deviate from standard practice, providing structured summaries with plain-language explanations.
Financial Research: The 122B-A10B model powers earnings research assistants for investment teams. It analyzes earnings presentation slides containing charts, tables, and management commentary to extract key financial metrics, interpret trends, and generate analyst summaries suitable for morning briefings.
Deployment and Integration
Microsoft Foundry users can deploy these models through multiple pathways. The Hugging Face collection in the Foundry model catalog allows direct deployment to managed endpoints with just a few clicks. Alternatively, users can start from the Hugging Face Hub, select any supported model, and choose "Deploy on Microsoft Foundry" to provision secure, scalable inference endpoints automatically configured in Azure.
All models feature a 262,144 token context window and support 201 languages, making them suitable for global deployments. The models are released under Apache 2.0 license, providing flexibility for commercial and research applications.
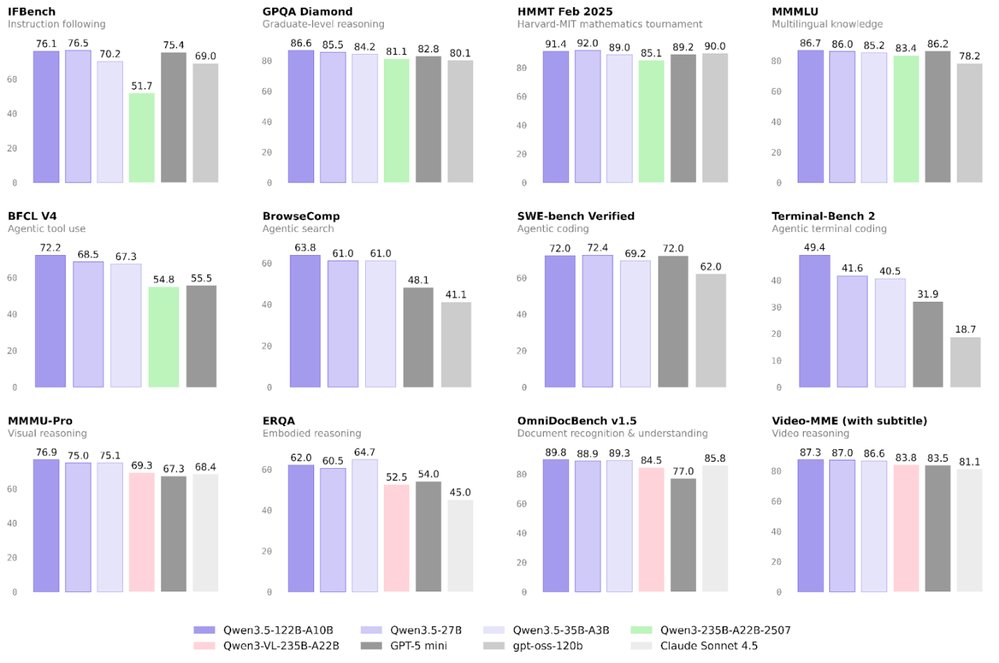
Performance Context
Figure 1 demonstrates that Qwen3.5 models achieve comparable performance to frontier models of larger sizes, particularly on vision-language reasoning tasks like MMMU and MathVista. This efficiency makes them attractive options for organizations seeking frontier-class multimodal performance without the computational overhead of the largest models.
The Qwen3.5 Medium Model Series represents Microsoft's continued investment in providing diverse AI capabilities through Foundry, giving developers access to state-of-the-art multimodal models that balance performance, cost, and deployment flexibility.
Comments
Please log in or register to join the discussion