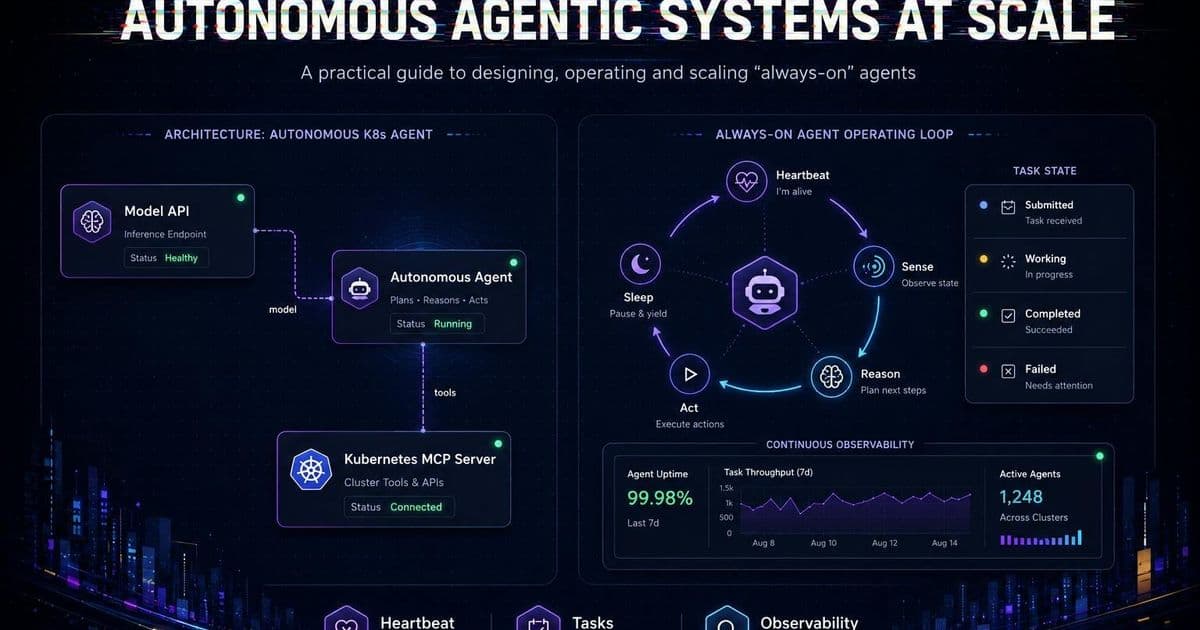
Alejandro Saucedo walks through the design choices, tooling, and operational concerns of building autonomous, always‑on AI agents, showing how they differ from single‑shot bots and what infrastructure is needed to keep them reliable at scale.
 )
)
Introduction
The hype around large language models often focuses on one‑off prompts, but a growing class of applications needs agents that run continuously, react to new data, and coordinate with peers. Alejandro Saucedo’s new guide, Autonomous Agentic Systems: A Practical Guide to “Always‑On” Agents, breaks down the problem into concrete components and offers a toolbox that works today, not in some distant future.
The problem these agents solve
Traditional chat‑oriented bots excel at answering a question and then shutting down. In contrast, always‑on agents must:
- Maintain state across interactions, remembering context that spans days or weeks.
- Monitor external signals (e.g., sensor feeds, market data, ticket queues) and trigger actions without a user explicitly prompting them.
- Collaborate with other agents, sharing goals and delegating subtasks.
- Self‑heal when a downstream service fails, ensuring the overall workflow keeps moving.
These capabilities open up use‑cases such as autonomous supply‑chain orchestration, real‑time compliance monitoring, and continuous personal assistants that schedule meetings, file expense reports, and even negotiate contracts on the fly.
Core architectural blocks
Saucedo’s guide groups the architecture into four layers, each with concrete open‑source options:
1. Agent Runtime
The runtime is the process that hosts the language model, executes tool calls, and persists short‑term memory. Two implementations dominate:
- AutoGPT‑Core – a lightweight Python loop that supports tool‑calling via OpenAI function calls or LangChain adapters.
- CrewAI – adds a task‑graph scheduler, making it easier to define multi‑step pipelines.
Both expose a simple run() API that can be wrapped in a container and orchestrated by Kubernetes.
2. Persistent Memory Store
Short‑term context lives in a vector store (e.g., Pinecone or Weaviate). For longer‑term facts, a relational DB with JSONB columns (PostgreSQL) works well, especially when combined with change‑data‑capture to keep the vector index up‑to‑date.
3. Observability & Telemetry
Running agents 24/7 means you need to know when they drift or stall. The guide recommends the KAOS framework (Kubernetes‑aware observability stack) paired with OpenTelemetry instrumentation and SigNoz for dashboards. Example snippets show how to emit custom spans for each tool call, making it possible to trace a chain of actions across multiple agents.
4. Coordination Protocol
When several agents need to negotiate, a lightweight protocol called A2A (Agent‑to‑Agent) is described. It builds on HTTP/2 streams and JSON‑RPC, allowing agents to publish intents, subscribe to events, and negotiate task ownership without a central broker. A minimal reference implementation lives in the guide’s GitHub repo.
Building an always‑on weather‑alert bot – a step‑by‑step example
Saucedo walks through a concrete project: a bot that watches a public weather API, detects severe conditions, and automatically creates incident tickets in ServiceNow.
- Define the intent – a JSON schema describing the alert (location, severity, timestamp).
- Set up the runtime – use AutoGPT‑Core with a
weather_monitortool that callsrequests.geton the API. - Persist state – store the last‑seen alert in PostgreSQL; embed the description in Pinecone for similarity search.
- Add observability – instrument the
weather_monitorcall with an OpenTelemetry span; configure SigNoz to alert on latency > 2 seconds. - Coordinate – if another agent (e.g., a logistics planner) also needs the alert, they subscribe to the
weather_alertevent via A2A, receiving the intent in real time.
The guide provides the full Dockerfile and a Helm chart, making the deployment reproducible on any cloud.
Trade‑offs and pitfalls
Even with a solid stack, always‑on agents face practical limits:
- State bloat – storing every interaction can overwhelm vector stores; periodic summarization (using a summarizer model) is essential.
- Tool‑call latency – external APIs add unpredictable delay; the guide suggests a circuit‑breaker pattern to fall back to cached data.
- Security – agents that can invoke arbitrary tools become attack surfaces. Saucedo recommends sandboxing tool execution with
gVisorand limiting API keys to scoped tokens. - Model drift – as the underlying LLM updates, prompts may behave differently. Continuous A/B testing of prompt versions is advised.
Where the ecosystem stands
The guide positions the current tooling as “production‑ready enough for early adopters.” Companies such as Zalando (where Saucedo works) are already piloting always‑on agents for inventory reconciliation, and the EU Commission is funding a cross‑border project to standardize the A2A protocol.
Closing thoughts
Autonomous agentic systems are moving from research demos to services that need the same reliability guarantees as any microservice. By focusing on runtime stability, observable state, and a clear coordination contract, developers can avoid the most common pitfalls and start delivering value today.
Alejandro Saucedo is an AI expert at the UN & European Commission, board member of the ACM, and director of AI, Data & Platform at Zalando. Follow him on Twitter.
Comments
Please log in or register to join the discussion