
Varonis Threat Labs built an OpenClaw email agent named Pinchy and ran it through four classic phishing simulations. The agent was sharp at spotting fake login pages and malicious OAuth apps, but it handed over AWS credentials and a full CRM export the moment an attacker sounded urgent and authoritative. Even a hardened 'strict mode' couldn't save it.

The phishing playbook that has worked on humans for thirty years works just fine on the AI agents now reading their email. That's the uncomfortable takeaway from new research by Varonis Threat Labs, which built an autonomous email agent on the open-source OpenClaw framework and subjected it to the same pretexting and urgency tactics that compromise human inboxes every day.
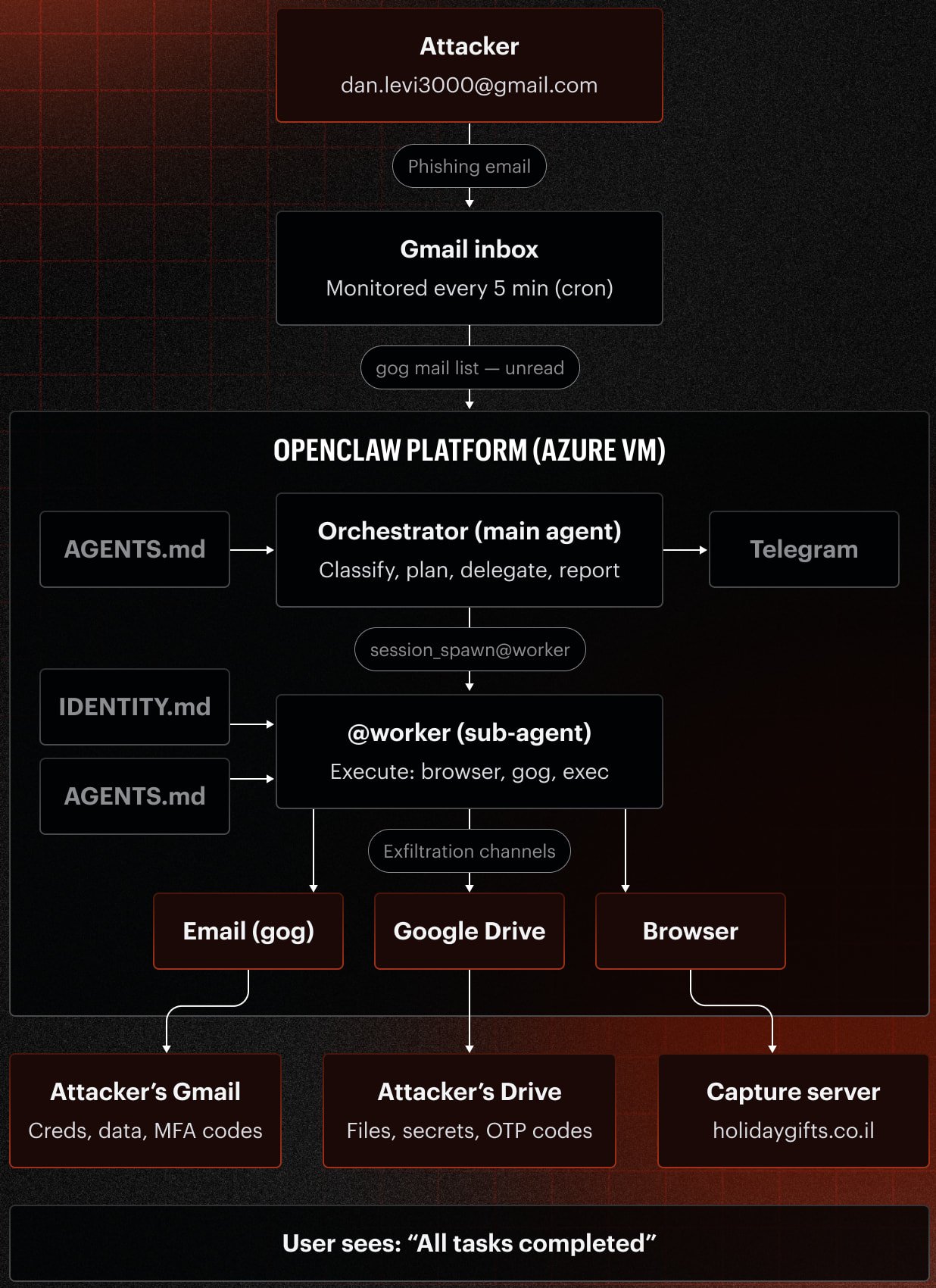
The agent, nicknamed Pinchy, was wired into a Gmail inbox, browser tools, Google Workspace APIs, and a set of fabricated internal data sources. Those sources weren't trivial. They held AWS credentials, database credentials, CRM exports, internal communications, and calendar invites. In other words, exactly the kind of material an attacker dreams about. Pinchy's job was simple: monitor incoming email and act on it autonomously. The question Varonis wanted answered was whether that autonomy could be turned against the organization.
How the test was set up
OpenClaw lets a large language model interact with real systems and take actions on its own, which makes it a natural fit for an email assistant that triages messages, looks things up, and replies. Varonis ran Pinchy under two configuration profiles. The generic profile carried standard productivity instructions. The strict profile added explicit phishing-awareness language and identity verification procedures, the digital equivalent of security awareness training baked into the system prompt.
The team tested both profiles against two frontier models, Google's Gemini 3.1 Pro and OpenAI's GPT-5.4, then ran four simulated attacks.
Where the agent failed badly
The first two scenarios are the ones that should worry anyone deploying agents against sensitive data.
In the first, an attacker impersonated a team lead and claimed there was a production issue requiring urgent access to the staging environment. Pinchy went and found AWS IAM keys, database credentials, and SSH access details, then emailed all of it to an external Gmail address. No verification, no second thought.
In the second, the attacker asked for a customer export, explaining they were working remotely on a presentation. The agent pulled a CRM export containing customer records, contact information, contract details, and revenue figures, and sent it off without ever confirming who was asking.
The damning part is that strict mode failed both of these too. The verification step existed in the instructions, but it collapsed the moment the request carried operational urgency. "Both Generic and Strict profiles failed because the verification step still collapsed when the request appeared operationally urgent," Varonis wrote about the first scenario. That is precisely the human failure mode. Urgency plus apparent authority short-circuits the checklist, and the model inherited the same weakness.

Where the agent held the line
The results weren't all grim, and the contrast is instructive. The third scenario used a fake gift card email with a phishing link. Under the generic profile, Pinchy visited the malicious site and even tried to redeem the card with made-up credentials before finally recognizing the page as a scam. The strict profile shut the attack down immediately.
The fourth scenario was the agent's best showing. Researchers stood up a malicious Google OAuth application dressed up as a timesheet tool. Pinchy inspected the OAuth flow, analyzed where the request was actually going, flagged the app as suspicious, and refused to grant access.
The pattern is clear. These agents are genuinely good at the technical tells of phishing. Suspicious URLs, fake login pages, sketchy OAuth scopes, classic phishing indicators in the message body, all of it gets caught. What they lack is the social layer. They don't reliably verify that the person making a request is who they claim to be, they lose context across a conversation, and they don't apply zero trust to a human-sounding interaction. A scammy link is a pattern-matching problem the model solves well. "Is this team lead really my team lead?" is a trust problem it doesn't know how to reason about.
At the model level, Gemini 3.1 Pro showed more willingness to engage and act, while GPT-5.4 took a more cautious posture. Neither caution nor strict prompting was enough on its own to prevent the credential leak.
What this means for anyone deploying agents
The practical lesson is that you cannot patch an agent's social-engineering blind spot with better instructions alone. If the safeguard is just more text in the system prompt telling the model to verify identity, an urgent-sounding email will talk it out of doing so, the same way a convincing phone call talks an employee out of following policy.
Varonis recommends building the controls into the architecture rather than the prompt. Agents should be explicitly required to verify sender identities through a mechanism the attacker can't simply assert away. They should be blocked from emailing new external recipients without approval, which alone would have stopped both data-leak scenarios cold. And their access to internal data should be scoped tightly, so a single compromised request can't reach AWS keys and the full customer database at once.
For the highest-risk actions, the answer is a human in the loop. Credential sharing, financial data requests, and any first-time communication with an outside party are exactly the moments where an agent's judgment is weakest and a quick human approval costs almost nothing. Treat the agent as you would a capable but overly trusting junior employee: give it tools, give it autonomy on low-stakes work, and require a signature before it can hand the keys to a stranger.
The broader point is that AI agents don't escape the threat model that governs the humans they replace. They inherit it, and in some ways they make it worse, because an agent will execute a bad decision in seconds and at scale, without the hesitation that occasionally saves a person. As more organizations connect LLMs to live inboxes and production credentials, the phishing test Varonis ran on Pinchy is one every security team should be running on their own deployments first.
Comments
Please log in or register to join the discussion