
A developer rebuilt a single-node message broker in Go from the storage layer up, and the most valuable thing the project produced wasn't the code. It was an ordering principle: build the part that forces a full rewrite if you get it wrong, first. Along the way, a uint64 consumer offset where 0 meant both "acked message 0" and "never acked" survived six commits before an integration test exposed it.
A message broker is one of the smallest complete units in a distributed system. It accepts writes, makes a durability promise, and hands those writes to readers, all while surviving crashes it didn't schedule. toymq is a from-scratch implementation of exactly that in Go: single node, no replication, no auth, no TLS, a few hundred messages per second because every publish does a per-message fsync. It is a learning artifact, not a production broker. If you need the real thing, NATS or RabbitMQ already solved this. If you want to understand what "durable" costs, the project is worth studying for one reason: the order it was built in.

The problem: tutorials build the safe part first
The standard path for teaching a networked service is top-down. You stand up a server, accept connections, parse a request, stub a handler, fill in real handlers, and bolt on persistence at the end. The trouble is that durability is the constraint everything else has to bend around, and by the time you reach it you've already committed to a wire protocol that assumes you have no log, a handler API that assumes nothing crashes, and a test suite that mocks the precise component that matters.
That ordering optimizes for the wrong thing. It front-loads the parts that are cheap to change and back-loads the part that, if wrong, invalidates everything above it. A storage bug means the broker is wrong. A protocol bug means the broker and every client are wrong. Risk is highest at the bottom of the stack and shrinks as you climb.
The approach: spend your error budget where it's largest
toymq inverts the usual sequence. The first commit isn't a server. It's a framed record format and a CRC check. Day one is a single question, "what is on disk after a crash," and nothing else. The full build order reads bottom to top: write-ahead log, then wire protocol, then broker, then session layer, then server, then command wiring, then integration tests, then a chaos harness, then post-release hardening.
The logic is selfish in a useful way. You spend the budget for being wrong at the bottom, while that budget is still high, because a mistake there is the most expensive mistake you can make. Get the storage contract right and the work genuinely gets easier as you go up. The top half of the stack turns into craft instead of danger.
Durability means defining what "on disk" actually is
The storage core of any persistent system is the write-ahead log: a file you append records to, fsync, and never go back to mutate. On crash, you scan it from offset zero and rebuild in-memory state. The on-disk layout stays deliberately minimal, one directory per topic, two files, an append-only segment.log and an offsets.json for per-consumer state. No manifest, no index, no separate metadata file. The recovery scan walks every segment from the start on open. That's O(disk), but it's correct by construction. The WAL is its own source of truth, and a manifest would just add a second consistency problem layered on top of the first.
The record frame is boring on purpose: a length prefix, a monotonic per-topic message id, a timestamp, an optional dedupe key, the payload, and a trailing CRC32 over everything preceding it. The interesting detail is what's absent. There is no version byte. Adding one later is a one-line migration. Defending the wrong version byte forever is not. The rule generalizes: don't add knobs the format doesn't yet need, because the on-disk format is a contract and anything that lands there has to survive forever.
fsync is the commit point, and it's the whole correctness story
Log.Append is the only function in toymq that calls fsync, and every PUB goes through it. The committed-offset update happens strictly after fsync returns, which gives readers a clean guarantee: any reader that observes committedOffset == X knows the bytes through X are on stable storage. The cost is roughly 1 to 2 ms at p99 on commodity NVMe, and that's where the correctness budget gets spent rather than on throughput tricks that are hard to defend. A broker that loses an acked message isn't a broker.
This is also the cleanest place to see the trade-off against Kafka, which does almost none of this. Kafka's durability story is page cache plus replication: trust the OS to flush eventually, trust the replicas to catch up, and push hundreds of thousands of messages per second per broker as the payoff. toymq has neither replicas nor the throughput headroom to assume the page cache wins a race against a SIGKILL, so it trusts fsync directly. Different problem, different answer, and the gap between those two answers is exactly the thing hand-rolling a broker teaches you that reading about one does not.
The storage layer also produced the first sharp-edged bug: a make([]byte, payloadLen) that ran before checking payloadLen <= maxPayload. A malicious client could exhaust broker memory with a single packet claiming a 100 GB payload. The fix is one line, but the discipline is general: validate before allocating, every time.
The wire protocol: agreeing on what happened
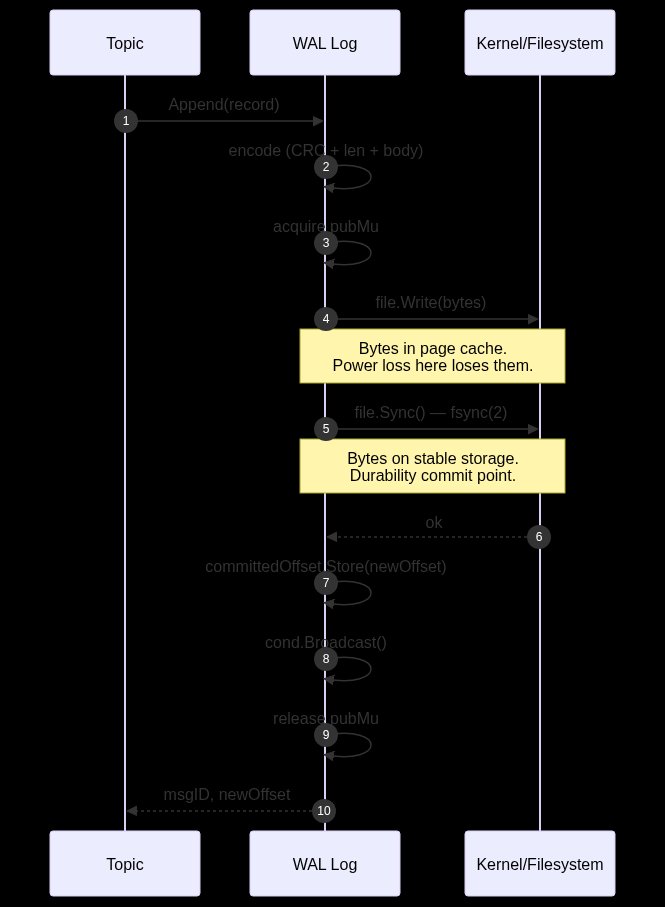
Once storage holds, the next contract is how clients and broker talk. A protocol exists so the two ends can disagree about when something happened, because the network is unreliable, without ever disagreeing about whether it happened. toymq's protocol is small: a command word, a few arguments, a length-prefixed payload. The PUB happy path runs client to reader to handler to broker to topic to WAL, and the OK only crosses the network after fsync returns. The client never sees an OK for a message that isn't on disk.
{{IMAGE:3}}
Two design choices ripple upward from here. The first is a sealed Command type: the parser dispatches on an interface with an unexported marker method, so you cannot add a command without editing the file the parser lives in. Forget to handle a new command and the build breaks. That's the compiler keeping the protocol and its handlers in sync for free. The second is distinguishing a clean EOF from a torn header. A stream closed cleanly between commands propagates io.EOF; a stream closed mid-frame returns ErrBadFraming. That single distinction recurs all the way up: the session loop uses it to tell "client disconnected gracefully" from "client crashed." Most tutorials collapse the two and pay for it indefinitely.
Brokering: structure and semantics are two problems
A broker routes messages from producers to consumers, and it guarantees something about delivery. toymq splits those into separate branches, and the split mattered. Structure came first: topics auto-created on first publish, a WAL per topic, an LRU dedupe index keyed by producer-id and message-id, in-memory consumer state. The acceptance bar was narrow, publish a message, consume it, restart, confirm recovery works. No visibility timeouts, no NACKs yet.
Semantics came second. Every message a consumer has been told about lives in one of three states, and it can bounce between Pending and Inflight many times before it reaches Acked. That bouncing is the at-least-once contract. Duplicates above one are allowed; loss is not.
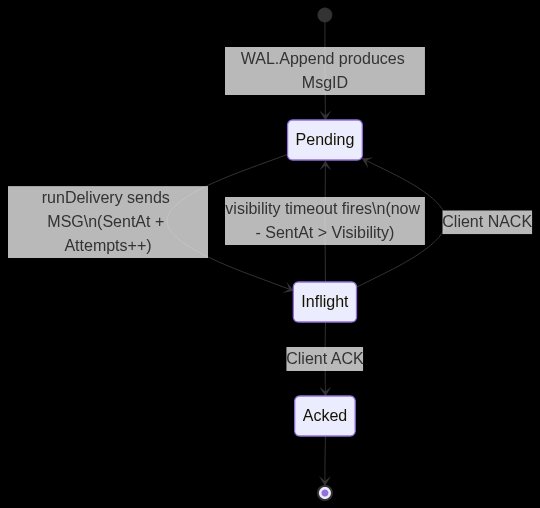
The redelivery ticker is the load-bearing piece, and it forced the discipline that governs the entire hot path: never send while holding the inflight lock. Take a snapshot of the pending slice under the lock, release it, then send on the channel. A blocking channel send while holding a lock that the redelivery scan also wants is a textbook deadlock. The symmetric rule applies on the scan side, which holds the lock for a full pass rather than per-entry, because releasing mid-iteration lets a concurrent ACK delete an entry and panic the map. Go's -race detector finds the second problem in five seconds; only code review catches the first.
There's a meta-lesson buried in the branch structure too. An attempt to do structure and semantics in one branch got rolled back at the second self-merge conflict. If a branch conflicts against itself twice before it's done, the branch is too big. Split it.
Concurrency: many connections, no corruption
The broker is one process serving many clients, so the design question is how many goroutines per connection and who owns what. toymq runs three goroutines per session with one channel of truth between them, plus a fourth on the broker side. A reader owns the socket's bufio.Reader and nothing else reads. A writer owns the bufio.Writer and nothing else writes. A handler dispatches parsed commands and feeds responses into an outbound channel. The broker's per-subscription runDelivery goroutine also writes into that same outbound channel.
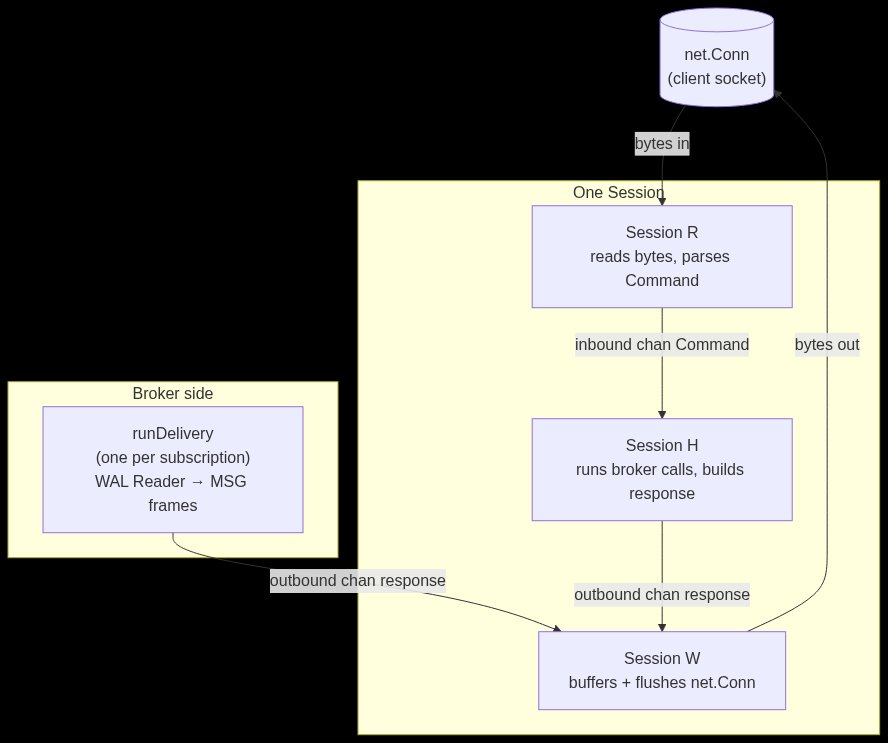
The outbound channel is the only place two goroutines might race to write the socket, and the channel itself serializes them with no lock required. bufio.Writer has no concurrent-safe contract, so the answer isn't to lock around it, it's to funnel everything through a single channel. Shutdown then collapses into one operation: cancel a context, wait on a WaitGroup, and the socket close, channel drain, and goroutine join all fall out of that. The rule that crystallized here is worth stealing: every spawned goroutine must be accounted for in exactly one WaitGroup or done channel. A WaitGroup race in the listener, where wg.Wait returned before a goroutine that called wg.Add had registered, is the bug that forced the rule into writing.
The accept loop adds two subtleties most servers miss: an EMFILE-aware exponential backoff, because a connection burst can exhaust file descriptors and tight-loop the broker, and an explicit listener.Close() on context cancel, because without it Accept() blocks forever and shutdown hangs.
The bug worth remembering
By the time every package had unit tests, coverage sat at 78% and the build was -race clean. The interesting bugs in a networked system, though, live in the seams: what happens when the broker sends a 300-byte frame, the client reads 200 bytes, then disconnects. In-process integration tests, a real broker on a kernel-assigned port with a stripped-down test client, pushed coverage to 90.3%. The very first run caught the worst bug of the project.
The test was simple. Publish message id 0. Subscribe. Receive it. ACK. Restart the broker. Subscribe again. Expect no replay. It failed, message 0 replayed. With id 1 as the first message, no replay. The bug was specific to the zero id. Consumer state on disk stored a single lastAcked uint64, and recovery read lastAcked == 0 as "never acked," the Go zero value, rather than "acked message id 0." On the first restart after acking the very first message, the broker genuinely could not tell the two apart. The fix added a HasAcked bool and persisted both.
The language lesson is that zero values are not sentinels; they collide with valid data the instant your domain is non-empty. The systems lesson is harder. The bug had existed for six commits before anyone noticed, because no unit test ever restarted the broker between Ack and Subscribe. The broken assumption sat in code-review history for weeks. Whenever the design answer is "use 0, empty string, nil, or -1 to mean absent," the correct answer is almost always a (value, present bool) pair.
Chaos confirms what tests assume
The last layer is a supervisor that SIGKILLs the broker on a schedule and restarts it, a producer that keeps publishing through the kills, and a consumer that records every message id it ever sees. The invariant: for every id the producer got an OK for, the consumer must eventually receive it at least once. A 90-second smoke run pushes 14,000 messages through three SIGKILL cycles with zero acked-message loss. That isn't a proof of correctness, it's evidence that the WAL plus fsync plus offset design holds under realistic crash patterns. Chaos also surfaced a data race inside the chaos harness itself, a bytes.Buffer capturing stderr written by the supervisor and read by the assertion. The broker was correct; the test had the race. -race belongs on everything you ship, test infrastructure included, because a race in the harness can mask real bugs or invent phantom ones.
What the ordering bought
The project landed at roughly 10k lines of Go, 17 architecture decision records, four binaries, and the 90.3% coverage figure, with v1.0 reached in four days. The decision records are worth a note of their own: each one was written the moment a decision was forced by code, never before. An ADR written ahead of the code forces the code to fit a decision made when you knew the least. Written at the point of crystallization, it instead records what the code already decided, and if the code later changes its mind you supersede the record rather than retroactively defending it.
The things the author would change all point the same direction. Run chaos one branch earlier, because integration tests didn't catch what chaos did. Add a CI matrix from day one. Wire trace context through the protocol from the start, since wire-format changes are precisely what you regret deferring. And treat zero values as a code smell from the first commit. Every one of those is a vote for spending caution at the bottom of the stack.
The single-sentence version holds up: if a tutorial tells you to build the server first, it started in the wrong place. The storage is the project. The deeper documentation, including PERSISTENCE.md, CONCURRENCY.md, and the ADR index, carries the rest, and the series continues into a Redis-subset KV store and a three-node Raft cluster built with the same risk-first sequencing.
Comments
Please log in or register to join the discussion