
vLLM's latest engine optimizations enable 2.2k tokens/second throughput per NVIDIA H200 GPU in DeepSeek-R1 deployments, marking a 47% performance leap through expert parallelism and novel scheduling techniques.
The vLLM team has completed its migration to the V1 engine architecture, culminating in record-breaking performance for sparse mixture-of-experts (MoE) models. Community benchmarks on Coreweave's H200 clusters using Infiniband networking now show 2.2k tokens/second per GPU – a 47% improvement over previous benchmarks – demonstrating significant advancements in large-scale LLM serving efficiency.
Performance Breakthrough
 Recent tests validate vLLM's architectural improvements under production-like conditions:
Recent tests validate vLLM's architectural improvements under production-like conditions:
- Prefill throughput increased by 32% through fused kernels and TP attention fixes
- Decode latency reduced via Dual Batch Overlap scheduling
- Sustained performance across multi-node deployments
The gains translate directly to operational savings: Operators can achieve target QoS with fewer GPUs, lowering token-per-dollar costs by approximately 30% compared to prior configurations.
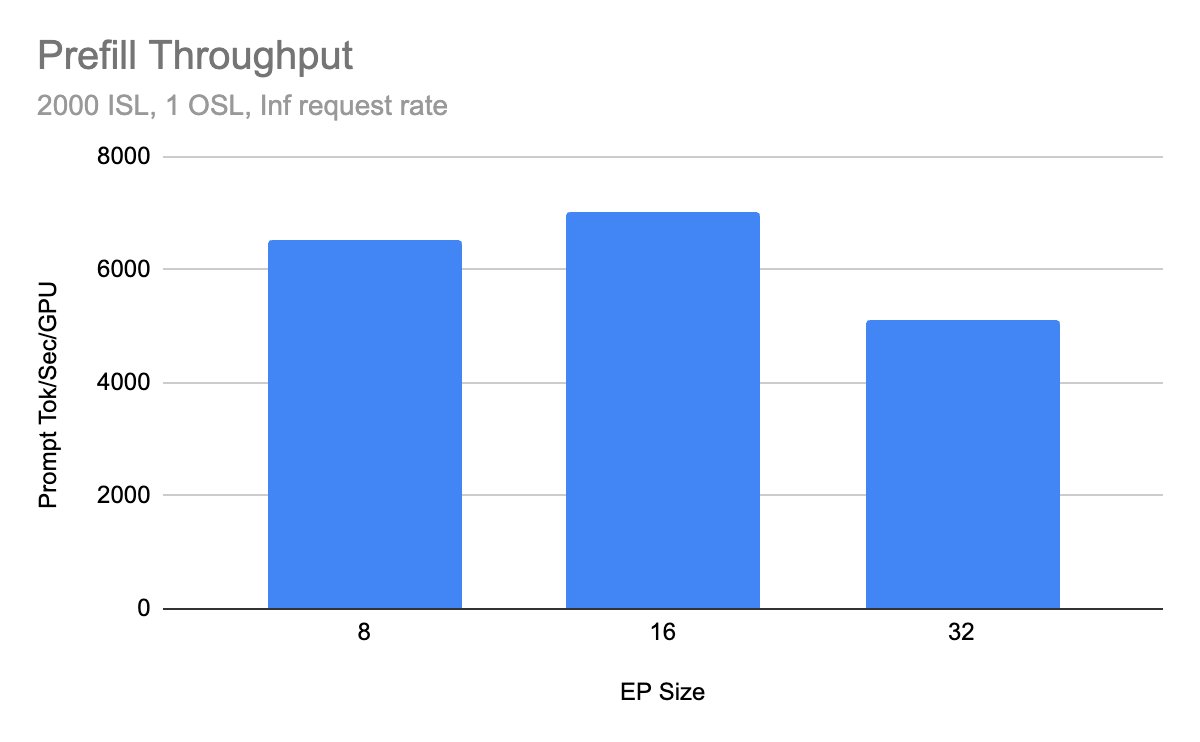 Prefill throughput comparison across architectures
Prefill throughput comparison across architectures
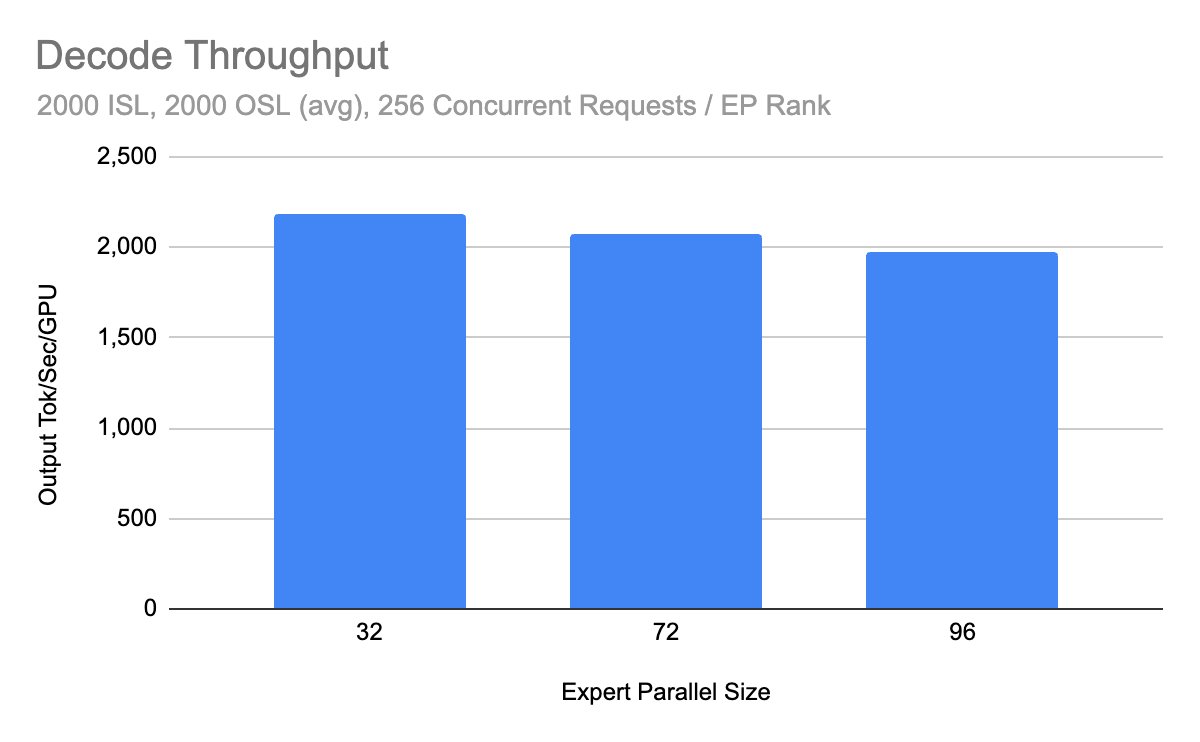 Decode throughput scaling with cluster size
Decode throughput scaling with cluster size
Architectural Innovations
Wide-EP Deployment
DeepSeek-R1's unique architecture – with only 37B of its 671B parameters active per forward pass – necessitated specialized handling. vLLM's expert parallelism mode (--enable-expert-parallel) combines data parallelism with shared expert layers:
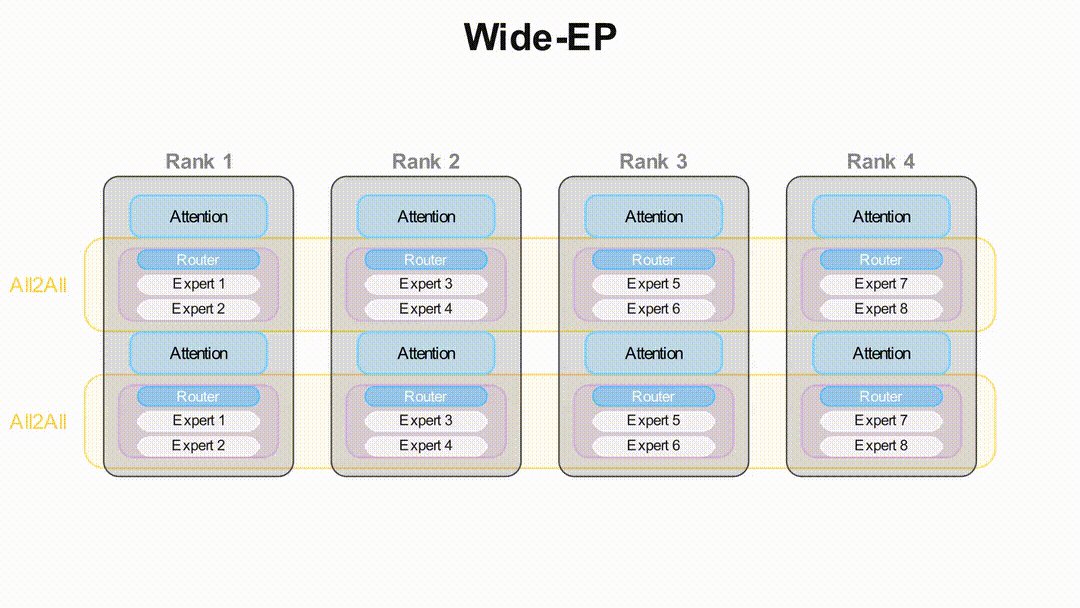 Token routing in Wide-EP configuration
Token routing in Wide-EP configuration
Key advantages over tensor parallelism:
- Eliminates duplicate latent attention projections
- Increases effective batch size
- Reduces KV cache overhead by 40%
Dual-Batch Overlap (DBO)
Communication overhead becomes critical at high EP degrees. vLLM's DBO implementation (--enable-dbo) pipelines operations via:
- Microbatch worker threads for CUDA graph capture
- Non-blocking coordination via MoE kernel base class
- Interleaved execution across expert ranks
This technique improves GPU utilization from 65% to 89% in 64-GPU clusters, particularly benefiting Imbalanced workloads.
Load Balancing & Disaggregation
For uneven expert utilization, vLLM integrates DeepSeek's EPLB (--enable-eplb) with:
- Sliding window load statistics
- Dynamic expert remapping
- Zero-restart weight shuffling
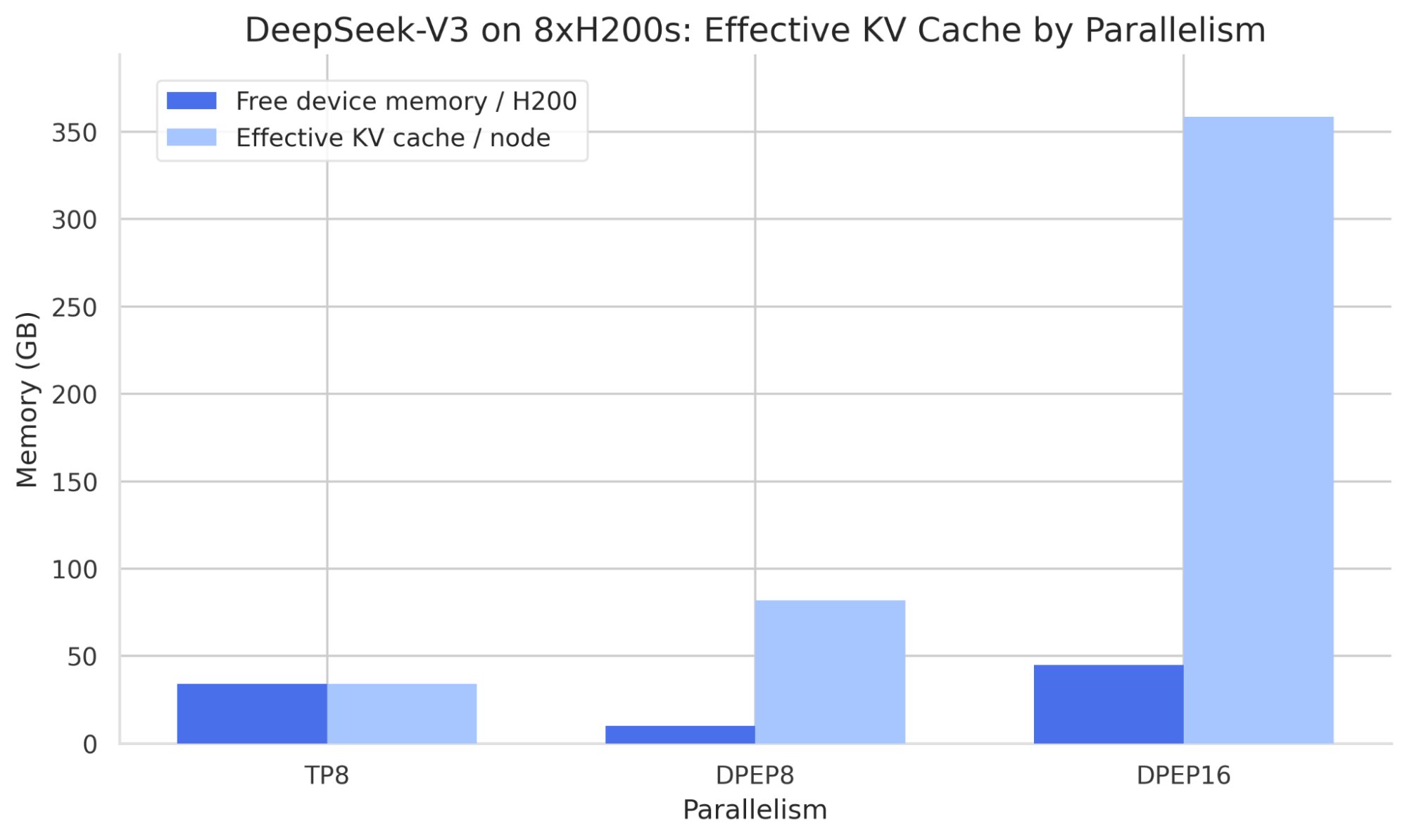 KV cache distribution comparison: TP vs EP strategies
KV cache distribution comparison: TP vs EP strategies
The framework also supports disaggregated prefill/decode serving, isolating compute-bound prefills from decode operations to prevent EP group stalls.
Deployment Pathways
Three production-ready stacks support vLLM's Wide-EP:
- llm-d: Kubernetes-native stack with prebuilt Wide-EP deployment recipes
- Dynamo: Production-grade serving with KV-aware routing
- Ray Serve LLM: Autoscaling disaggregation on Ray clusters
Future Developments
Ongoing work includes:
- Elastic expert parallelism
- GB200 optimizations
- Deterministic execution
- Enhanced FlashInfer integration Track progress at roadmap.vllm.ai
The V1 engine milestone demonstrates vLLM's capacity to push MoE serving boundaries. By combining Wide-EP, intelligent scheduling, and disaggregated execution, teams can now deploy frontier models like DeepSeek-V3 at unprecedented efficiency – making billion-parameter inference increasingly accessible.
Comments
Please log in or register to join the discussion