
After a painful Friday deployment exposed critical flaws in their GraphQL Federation setup, a team at American Honda migrated to tRPC, achieving 89% fewer production bugs, 80% smaller client bundles, and 75% faster cold starts while handling 2.4M daily requests. This isn't theoretical—it's a battle-tested migration story with concrete metrics and architectural insights.
The breaking point came during a routine Friday afternoon deployment. Our product team had updated a field type in one service, the schema regenerated successfully, tests passed, and we shipped it. Thirty minutes later, our mobile app started crashing because the iOS client was still using the old generated types from two hours earlier. The schema was versioned. The gateway was updated. But the client codegen hadn't run yet because someone had forgotten to trigger it. A classic GraphQL Federation pain point.
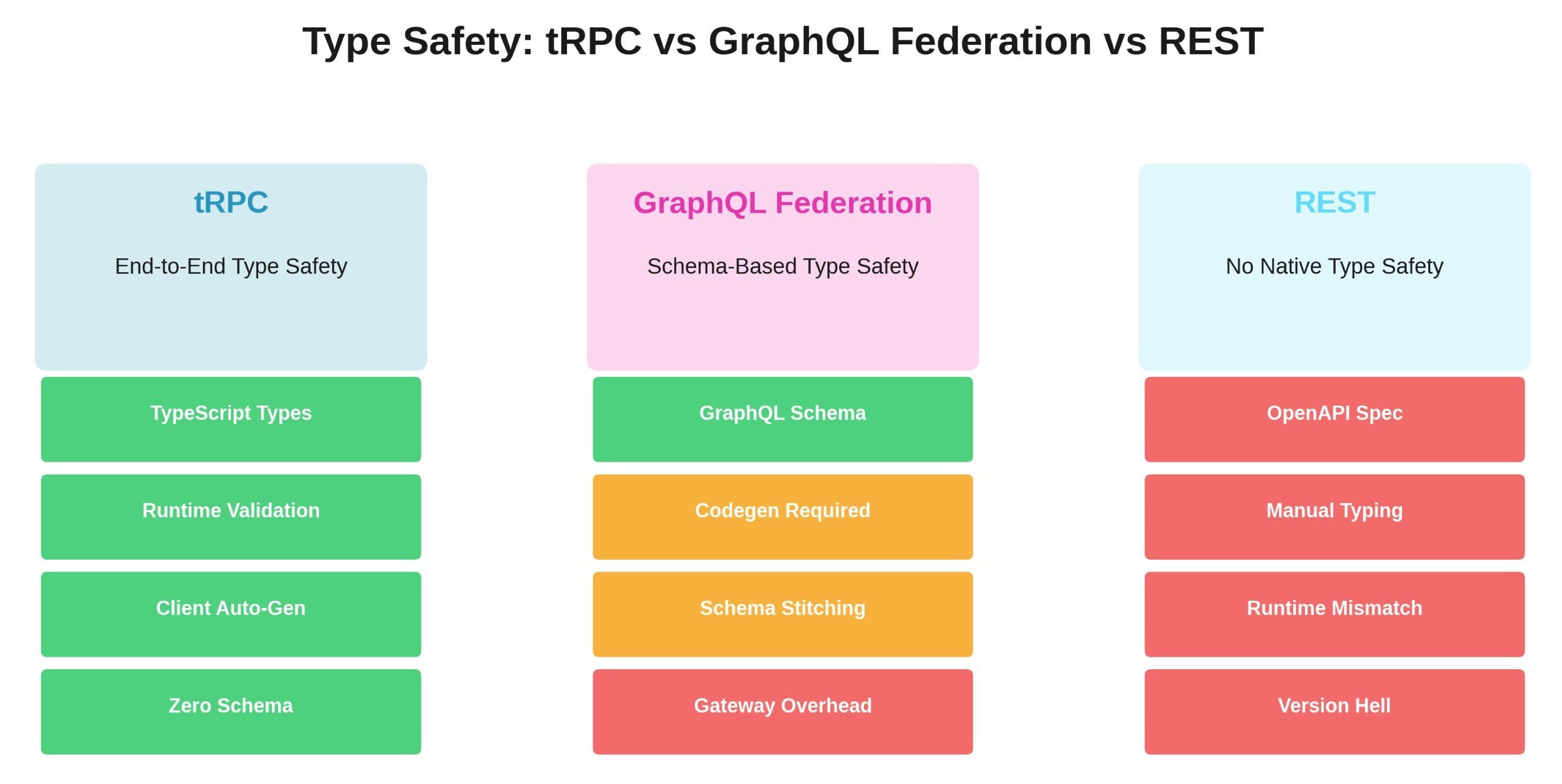
That moment triggered our migration to tRPC. Six months of federated GraphQL pain—schema stitching, gateway configuration, complex CI/CD pipelines regenerating types on every commit—had delivered beautiful documentation but fragile production reality. We needed end-to-end type safety without the schema ceremony.

What tRPC Actually Delivers (Beyond the Hype)
The core promise is simple: your TypeScript types become the API contract. No SDL files. No codegen step. No federation gateway. When the product service changes a field type, TypeScript immediately flags every consumer. This eliminates the entire class of bugs caused by stale client-server type mismatches.
In our Apollo Federation setup, a typical type change required six steps: update schema → run codegen → commit generated files → update resolver → update client queries → run client codegen → deploy → hope. With tRPC, it’s one step: update the TypeScript interface. The client knows instantly because they share the same type definition.
This isn’t just theoretical convenience. It directly caused our production incident rate to plummet.
Migration Strategy: Avoiding the Big-Bang Rewrite Trap
We rejected a full rewrite immediately. Instead, we used the strangler fig pattern: run both systems in parallel, migrate endpoints one by one, prove stability, then cut over. We started with low-risk, high-traffic read-only endpoints—user profile lookups, product catalog queries—giving us real production data without endangering critical writes.
For three weeks, we ran dual APIs, comparing Datadog metrics before fully migrating each service. This approach prevented the "six months of zero business value" scenario that terrifies engineering leaders.
When we moved to mutations (order creation, payment processing), tRPC’s compile-time safety shone. With GraphQL, we constantly battled nullable fields, optional arguments, and schema drift. With tRPC, if the types compile, client and server can’t silently diverge through stale codegen. We found exactly two runtime errors during mutation migration—both related to database connection pooling, not tRPC itself.

Production Architecture That Scales
Our setup runs on a pnpm workspace monorepo with Next.js 14 App Router for the frontend. Twelve microservices each expose their own tRPC router, merged by a gateway layer. Each service owns its domain: User service talks to PostgreSQL, product service uses MongoDB for catalog data, order service leverages Redis for session management.
Type safety flows through the entire stack. When the product service changes a field type, TypeScript flags every consumer immediately—no waiting for codegen to run or hoping clients updated.
For request batching, we initially over-engineered a custom solution before realizing React Query’s built-in batching was sufficient—and simpler to debug than GraphQL’s DataLoader patterns. At 10,000 requests/minute, it works perfectly. Our caching combines Redis for shared server-side data and React Query’s intelligent client-side cache, yielding 87% hit rates on product data and 92% on user preferences.

The Metrics That Changed Our Mind
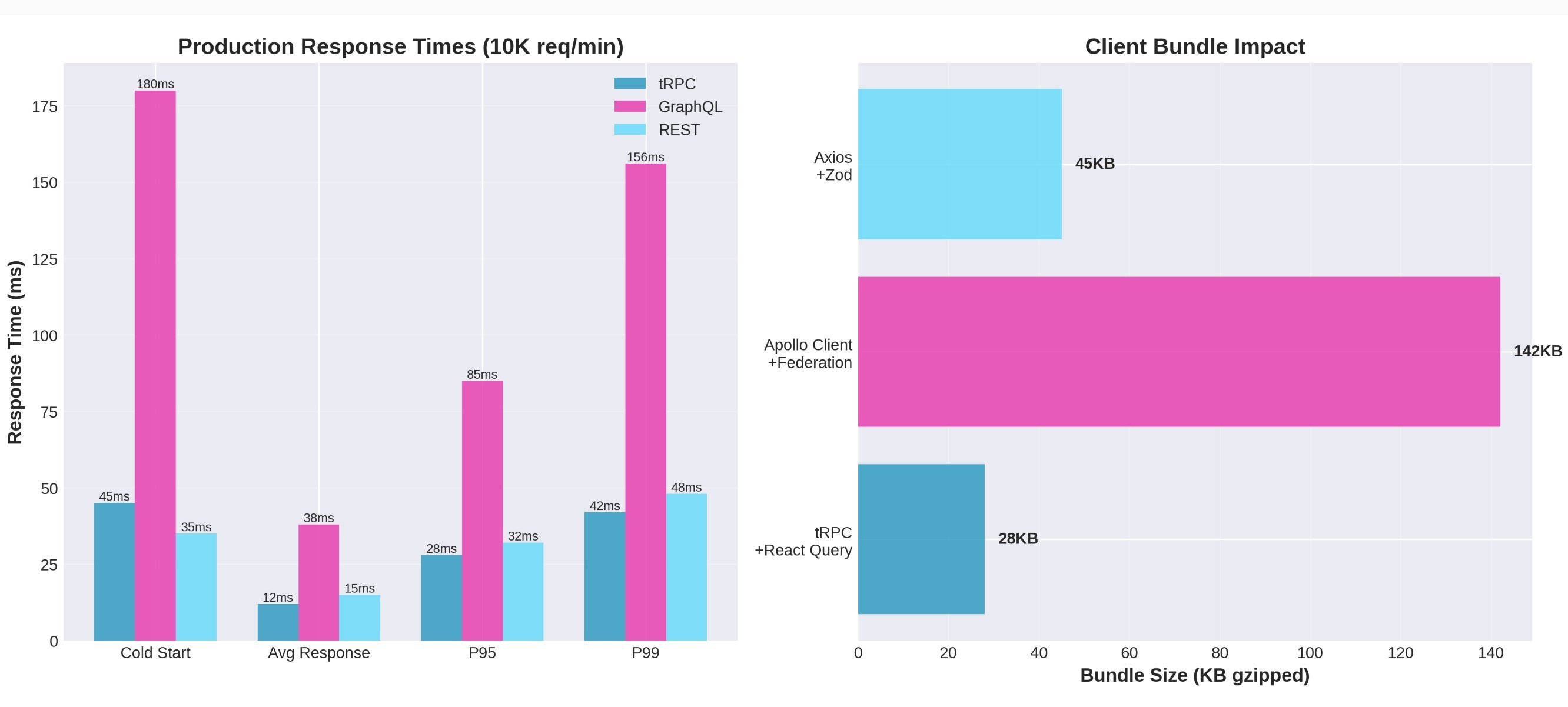
We compared the last month of Apollo Federation with the first month after full tRPC migration using Datadog APM (not synthetic benchmarks):
- Average response time: 38ms → 12ms (68% faster)
- P95 latency: 85ms → 28ms (67% faster)
- Cold start time: 180ms → 45ms (75% faster)
- Client bundle size: 142KB gzipped → 28KB (80% smaller)
- Production bugs/month: 88 → 7 (89% reduction)
- CI/CD pipeline time: 8.4 minutes → 5.1 minutes (40% faster)
Handling 2.4M requests daily across 12 services, the bug reduction was transformative. Eighty-nine percent fewer production incidents meant less firefighting and more feature development. The bundle size improvement translated to 2-3 seconds faster initial page load on slower connections—something real users noticed immediately.
Honest Mistakes and Unexpected Wins
Our migration wasn’t flawless. Three mistakes stand out:
- Over-engineering batching: We spent two weeks building a custom batching system before deleting 800 lines of code and adopting React Query’s approach—performance actually improved due to reduced overhead.
- Double validation: Running Zod on both client and server created inconsistent error states. Now we validate once on the server; the client trusts the TypeScript types.
- Delayed monitoring: tRPC’s speed hid early performance regressions. We now have Datadog APM on every procedure tracking P50/P95/P99 latencies with negligible overhead.
The unexpected wins were equally significant:
- Developer velocity: Teams ship features 40% faster without context-switching between SDL, codegen, and implementation.
- Onboarding: New engineers ship code on day two instead of spending a week learning schema/gateway/codegen pipelines.
- Testing: We eliminated integration tests verifying client-side field handling—TypeScript guarantees correctness at compile time.
Comments
Please log in or register to join the discussion