
Hugging Face's Open R1 project just completed the first leg of reproducing DeepSeek-R1, releasing a 350k-trace reasoning dataset and a 7B model that matches DeepSeek's distilled numbers. The result says something about where reasoning models came from, and how reproducible they really are.
When DeepSeek-R1 landed in January 2025, the reaction split into two camps almost immediately. One side treated it as proof that frontier reasoning could be done cheaply and outside the usual labs. The other side noted that a model with open weights and a tech report is not the same thing as an open recipe. You could download R1, but you could not rebuild it, because the training data, the synthetic generation pipeline, and the reinforcement learning setup were described in prose, not shipped as code.
Open R1, Hugging Face's attempt to close that gap, has now marked the completion of its first major milestone. The project's stated goal is blunt: build the missing pieces of the R1 pipeline so anyone can reproduce and extend it. As of the May 2025 update, step one is done. That step was never the glamorous part, but it is the part that tells you the most about how these models are actually made.

The trend underneath the headline
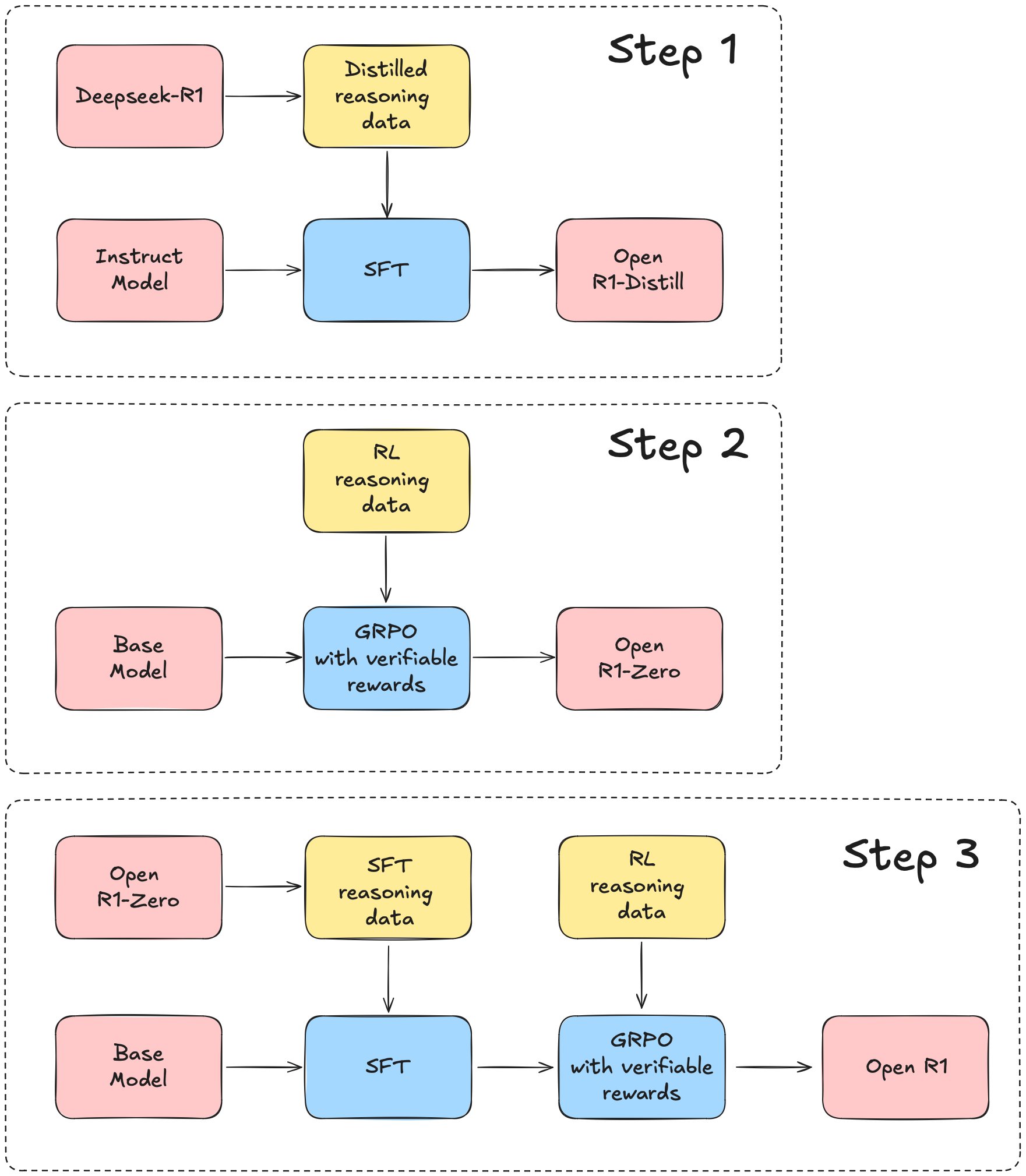
The pattern worth watching here is not "open source catches up to closed." It is the quiet industrialization of distillation as the default on-ramp to reasoning capability. Open R1's plan of attack lays it out in three stages: first replicate the R1-Distill models by distilling a high-quality corpus from DeepSeek-R1, then replicate the pure RL pipeline that produced R1-Zero, then show you can go from a base model to an RL-tuned one through multi-stage training.
Notice the ordering. Distillation comes first because it is the most tractable and the most reliable. You take an existing strong reasoning model, generate a large set of step-by-step traces, filter them, and fine-tune a smaller model on the result. The completed step one delivered exactly this: Mixture-of-Thoughts, a curated dataset of 350k verified reasoning traces spanning math, code, and science, plus a recipe to train OpenR1-Distill-7B.
The evidence
The numbers are the interesting part, because they are close enough to be boring, which is the point. OpenR1-Distill-7B, trained from the same base model as DeepSeek's own distilled 7B, posts the following against its target:
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench v5 |
|---|---|---|---|---|
| OpenR1-Distill-7B | 52.7 | 89.0 | 52.8 | 39.4 |
| DeepSeek-R1-Distill-Qwen-7B | 51.3 | 93.5 | 52.4 | 37.4 |
The Open R1 model edges ahead on AIME, GPQA, and LiveCodeBench, and trails on MATH-500. Within the noise these are the same model. That is a meaningful claim: starting from a public base model and an openly documented data pipeline, an outside team rebuilt the distilled reasoning behavior that DeepSeek reported.
The project also did the unglamorous work of reproducing DeepSeek's own evaluation numbers using lighteval, landing within one to three standard deviations across the whole distilled family from 1.5B to 70B. Anyone who has tried to reproduce a benchmark table knows how often this fails. The team is upfront about why their numbers wobble: AIME 2024 has only 30 problems, so they sample 64 responses per query to estimate pass@1, and variance across runs is still large.
Along the way the project shipped intermediate artifacts that are arguably more useful than the headline model. OpenR1-Math-220k provided 220k math traces distilled from R1. The CodeForces-CoTs release added 10k competitive programming problems with 100k solutions, and the project claims a 7B model trained on it can outperform Claude 3.7 Sonnet on the IOI24 benchmark while a 32B model can beat R1 itself on those problems. The training stack itself leans on TRL, vLLM, and GRPO, with code reward functions that execute generated solutions in sandboxes from E2B and Morph against real test cases.
The counter-perspectives
Here is where the consensus deserves some pressure. Calling Open R1 a "fully open reproduction of DeepSeek-R1" is accurate as a project title and premature as a description of what exists today. What has been reproduced is the distillation step, and distillation is, by construction, parasitic on an already-trained teacher. OpenR1-Distill-7B learned to reason by imitating traces generated from DeepSeek-R1. The hard scientific claim in the original R1 work was not that you can distill reasoning into a small model. It was that pure reinforcement learning on a base model, the R1-Zero recipe, can grow reasoning behavior from scratch without supervised reasoning data. That is step two, and step two is still open.
This matters because the two steps have very different implications. If distillation is the load-bearing technique, then open reasoning models are downstream of whoever trains the best closed teacher, and the capability ceiling is set elsewhere. If the from-scratch RL pipeline is reproducible at modest cost, the picture is genuinely different. The Open R1 roadmap itself acknowledges that step two will "likely involve curating new, large-scale datasets for math, reasoning, and code," which is a polite way of saying the expensive, uncertain part has not been derisked yet.
There is also a quieter caveat in the data work. The project ships a decontamination script based on 8-gram overlap, following the approach from the s1 paper, to strip benchmark contamination from training data. The fact that this tooling is necessary, and prominent, is a reminder that distilled reasoning datasets are exactly the kind of artifact where train-test leakage can quietly inflate the numbers everyone is celebrating. Open R1 deserves credit for surfacing the problem rather than hiding it, but it should temper how cleanly anyone reads those matching benchmark rows.
Skeptics of the broader "reasoning models are commoditizing" narrative have a fair point too. Reproducing a 7B distilled model on a node of 8 H100s is accessible to well-funded labs and serious academic groups, not to hobbyists. The GRPO training, multi-node vLLM serving, and sandboxed code execution described in the repo assume Slurm clusters and real GPU budgets. "Anyone can reproduce it" carries an implicit "anyone with a cluster."
What actually changed
Strip away the framing and a concrete shift remains. Before Open R1, the R1 results were a report plus weights. After it, there is a working, documented, openly licensed pipeline that takes a base model to distilled reasoning performance matching DeepSeek's, with the datasets, configs, and evaluation harness all public. That is real infrastructure, and the intermediate datasets are already showing up in other people's training runs.
The honest read is that Open R1 has proven the easy half of its thesis convincingly and left the hard half as a visible, unfinished construction site. The next time someone tells you reasoning models have been fully democratized, the useful question is which step they are pointing at. Step one is done and the receipts are solid. Step two is where the original claim of cheap, from-scratch reasoning will actually be tested, and that result is the one worth waiting for.
Comments
Please log in or register to join the discussion