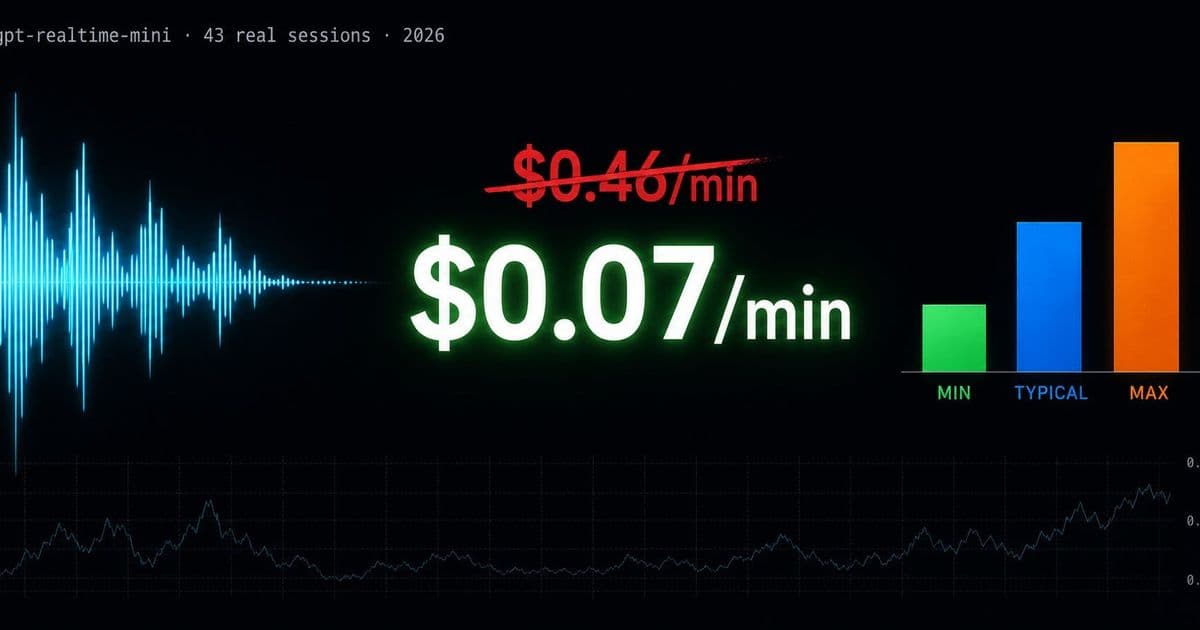
A lead front-end developer ran 4,000 real voice sessions through OpenAI's Realtime API and tracked the bills. The numbers tell a different story than the pricing page, and they explain why so many voice-AI startups quietly blow through their budgets.
Voice AI has a billing problem that nobody discovers until the invoice arrives. The pricing pages look approachable. A few cents per minute, a token rate that seems manageable, a cheaper "mini" tier for teams watching costs. Then the first month of real traffic lands and the spreadsheet stops matching the marketing.
Semianchuk Vitalii, a lead front-end developer at eyespy360, decided to stop guessing. He instrumented roughly 4,000 live sessions on OpenAI's Realtime API and measured what they actually cost, token by token, second by second. The results, published on HackerNoon, are the kind of ground-truth data that voice teams usually only assemble after they have already overspent.
The company behind the numbers
eyespy360 builds 360-degree virtual tour and inspection tools, the sort of product where a voice interface is not a gimmick but a genuine convenience. A user walking through a property or inspecting a site wants to talk, not type. That use case puts the OpenAI Realtime API squarely in the critical path, and it makes the per-session economics a product decision rather than a line item someone in finance worries about later.
That context matters, because the Realtime API is priced unlike the text completions most developers already understand. It bills audio input and audio output as tokens, and audio tokens are dramatically more expensive than the text tokens people anchor their intuition on. A conversation that feels short to a human can carry a surprising amount of billable audio in both directions.
The problem the data exposes
The gap Vitalii set out to measure is the one between estimated and actual cost. Most teams model voice spend with a clean assumption: average session length times a published per-minute rate. Reality is messier. Sessions include silence, interruptions, retries, and the model's own spoken responses, which can run longer than expected. Background noise gets transcribed and billed. A user who pauses to think is still holding an open audio stream.
The gpt-realtime-mini tier, positioned as the budget option, complicates the picture further. A cheaper per-token rate does not automatically translate to a cheaper session if the smaller model needs more turns to resolve the same task, or if it produces longer responses to compensate for less precise understanding. Cost per token and cost per completed conversation are different metrics, and only one of them shows up on the bill.
Measuring 4,000 sessions is enough to move past anecdote. At that volume the long tail becomes visible: the handful of sessions that run ten times longer than the median, the calls where audio output dominates, the difference between a quiet office user and someone on a noisy street. Averages hide all of this, and averages are exactly what most cost models are built on.

Why this matters for anyone shipping voice
The broader pattern here extends well beyond one API. Real-time AI inference is becoming a standard product feature, and its cost structure punishes the assumptions that worked for older API billing. With a text endpoint, a slow user costs you nothing while they read. With a streaming voice connection, idle time and audio both accrue charges. The unit economics of a voice feature can quietly invert the margins of an otherwise healthy product.
This is where measured data earns its keep. Knowing the actual distribution of session costs lets a team make concrete engineering choices: when to cut a session short, when to fall back to text, whether the mini model genuinely saves money for their traffic, how aggressively to trim silence before it reaches the API. None of these decisions can be made well from a pricing page. They require knowing what your own users actually do.
The traction signal
There is a market story buried in the methodology, too. The fact that a working developer at a production company felt the need to run this experiment says something about where voice AI sits in 2026. The technology is past the demo stage and into the budgeting stage. Teams are no longer asking whether the Realtime API works. They are asking whether they can afford it at scale, and they are not finding satisfying answers in official documentation.
That is usually the moment a category matures. Cost optimization tooling, observability for token spend, and middleware that sits between applications and the OpenAI API tend to follow once the early adopters start publishing their real numbers. Vitalii's session-level data is a small contribution to that shift, but it points at a genuine opening: the companies that understand voice-AI cost behavior before their competitors do will price their own products more confidently.
The honest takeaway is unglamorous. Voice AI is affordable when you measure it and expensive when you assume it. Four thousand sessions is one developer's answer to a question every voice team should be asking about their own traffic, and the smart move is to run the same experiment rather than trust anyone else's averages, including these.
Comments
Please log in or register to join the discussion