Machine Learning
PrismML launches 1‑bit and ternary Bonsai Image 4B models for on‑device diffusion generation
5/31/2026

Machine Learning
BitCPM-CANN: 1.58-Bit Training Framework Opens New Path for Memory-Efficient AI on Domestic Hardware
5/26/2026

LLMs
Qwen 3.7 Max: Evaluating Alibaba's Long-Running LLM Claims
5/25/2026

AI
ByteDance's Lance: A Multimodal Model for Local AI Workloads
5/25/2026

AI
Zhipu AI’s GLM‑5.1‑highspeed API claims 400 tokens/s – what the numbers really mean
5/22/2026
AI
Redis Creator's DS4 Project Brings Frontier AI to Local Hardware
5/15/2026
LLMs
antirez’s ds4: A Narrow, Metal-Only Inference Engine for DeepSeek V4 Flash
5/7/2026
AI
sectorllm: Pushing the Boundaries of Minimalist AI with a 1369-Byte Llama2 Engine
5/5/2026

LLMs
LLMs vs. SLMs: Practical Trade-offs in Modern NLP Applications
4/27/2026
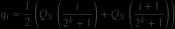
Machine Learning
Gaussian Precision: How NF4 Quantization Transforms LLM Weight Distribution
4/19/2026
Machine Learning
The Shrinking Universe of Numbers: FP4 and the Precision Revolution in Computing
4/18/2026

LLMs
Google's TurboQuant Compression Enables Faster LLM Inference on Modest Hardware
4/15/2026
Machine Learning
TQ4_1S Weight Compression: Breakthrough in Model Quantization for llama.cpp
4/4/2026